New Ways to Address Modern Privacy Challenges
The last 12 months have been busy ones for IronCore with new products, new features, major leaps in performance, usability, and more.
If you’re like us, you may find it hard to look away from the torrent of news these days. Amidst the whirlwind that is 2020, we want to step back and recap the progress we’ve made with our product line over the past year.
New Product Names
We’ve recently changed the names of some of our core products to acknowledge that they’ve grown beyond their original use cases with new features.
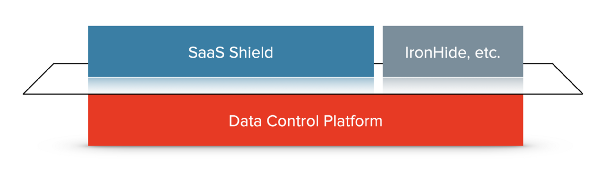
Data Control Platform
Our zero-knowledge SDKs, which support cryptography-based access controls, and which we used to call our end-to-end encryption toolkit, are now components of the Data Control Platform. We made this change for a few reasons, but one of them is that while fundamentally what we do is powered by cryptography, we also go beyond that. For example, we have a strong emphasis on audit trails, data management policies, and other aspects that give data owners control of their data.
In addition to the client-side use cases you commonly think of in end-to-end encryption scenarios, we also support server-side encryption and decryption, and mixes of the two. By expanding the scope of the name, we hope people will consider broader use cases where they want to tightly manage and secure data.
SaaS Shield™️
Our Customer Managed Keys for SaaS product is now known as SaaS Shield. As with our core platform, we’ve expanded the product’s functionality. We support customer held encryption keys, and we’ll soon release support for near-real-time streaming of logs to SaaS customers’ security logging infrastructure. This log stream will first include data access events but will soon be joined by other events that are interesting for security and compliance reasons, such as changes to users, groups, and permissions.
Data Control Policies and Editor
One common use of our Data Control Platform is to make sure that only specific users and systems can see particular classes of information. At the core, we do this with public key cryptography and groups. But it can be cumbersome to manage groups in more complex systems. So we released our initial version of policies last year.
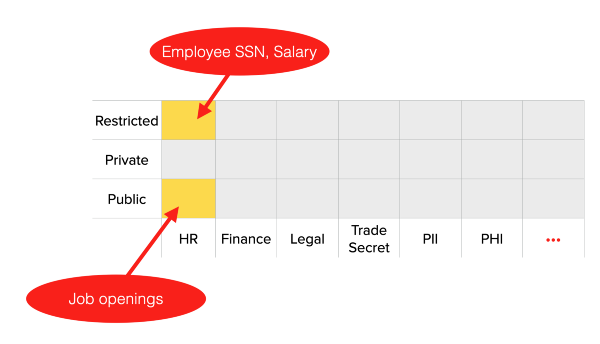
Data control policies allow you to tag data with a sensitivity level (customizable, but for example, low/medium/high or public/private/restricted) and a category (also customizable, but for example, HR/Finance/Legal/Health).
And you can then determine which sets of users (employees or even customers) should be able to access each of the combinations of sensitivity and category.
Until recently, setting up these policy rules meant handwriting configuration files. We’re pleased to announce that we now have a graphical policy editor for administrators to create and maintain their data policies.
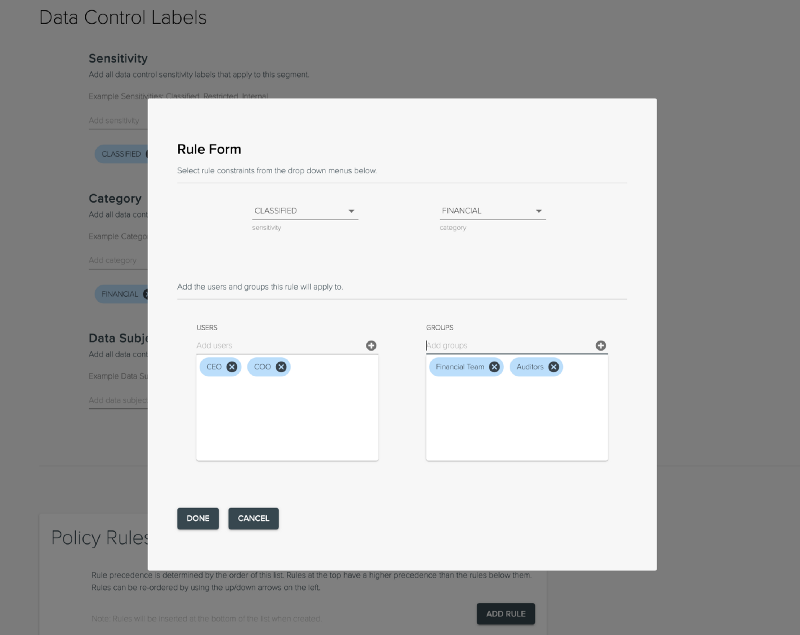 New graphical policy editor for data control policies
New graphical policy editor for data control policies
Encrypted Field Search

In the Data Control Platform, IronCore now supports searching and filtering on encrypted data, including substring searches.
This is a huge deal.
One of the most common things that we hear when we tell people they should be encrypting and controlling their data is a worry it will become useless. For example, encrypting a customer’s home address sounds great until there’s a business reason that requires someone to pull up the records of all customers who live in a particular city.
Previously, you needed to maintain a separate index to look records up by a particular attribute (which could leak a lot of sensitive data), or to pull in all the records and decrypt and filter them in the client. Now the search and filter operations can happen on the server without the server seeing any unencrypted data.
This feature is useful specifically for searching on fields that typically hold small amounts of data (roughly ranging from a word to a paragraph in size). IronCore does not yet support a secure encrypted search method for larger text sizes such as full document search.
Expanded Language and Platform Support
Our goal is for there to be zero excuses for not tightly controlling and securing private data. We think this is how modern applications should be built and we want this to be available to everyone, everywhere.
In doing this, you shouldn’t have to trust us. That means we, IronCore Labs, should never have access or the ability to access anyone’s private data. We never see plaintext data or private keys, which means that all encrypt and decrypt operations happen on client devices or inside our customers’ infrastructure. Consequently, we must support a variety of platforms and languages.
We’ve worked hard to build broad support. We’ve invested a tremendous amount of time, money, and energy to make our libraries portable. Below is our current support list. If your preferred language or platform isn’t listed below, talk to us.
Data Control Platform Language Support
In the past year we’ve expanded our language support so that we now support all of these languages:
- Rust
- Java
- Scala
- TypeScript
- JavaScript
- C++
- Swift (beta)
And we support the following platforms:
- Web Browser (with WebAssembly)
- NodeJS
- macOS native
- Linux native
- Windows native
- Android native
- iOS native (beta)
SaaS Shield Language Support
SaaS Shield is a server-side encrypt/decrypt solution that does not require the breadth of support needed by our Data Control Platform. However, any language and environment supported by the Data Control Platform could be supported by our SaaS Shield SDKs. Contact us if you’d like to request support for something not listed below.
Run-times:
- JVM
- NodeJS
We support TypeScript and JavaScript on NodeJS and also any JVM language including Java and Scala. These should work on any platform, but we specifically test for and support Linux server environments.
Seamless Private Key Rotation
With IronCore’s Data Control Platform, it’s always been easy to rotate device keys and user keys when data is encrypted to groups instead of directly to users. Using our multiparty-computation for users and groups, we are now able to rotate the private keys for users even if data is encrypted directly to them, without needing to change already encrypted data.
One key driver of this functionality is the chicken and egg problem often faced in end-to-end encryption systems: how can we encrypt data to a person who hasn’t yet generated their keys?
This problem is particularly bedeviling when the goal is to encrypt the data of millions of consumers, where each consumer’s data is encrypted to them and decryption rights are delegated from them back to the company in a revocable way. We call this our GDPR pattern and it works great, but until recently, we didn’t have a good way to import an existing repository of data and encrypt it all at once to users without existing keys.
Now we can.
With private key rotation, a server process can generate keys for a user, encrypt their data to the public key, and delegate decryption back to the company. The private key is encrypted and escrowed using a model that splits trust between IronCore and our customer.
This process leaves the users’ keys in a partially compromised state. The server systems have seen the private keys of these users, and if someone managed to capture those keys, then the users’ data is compromised. Note that at this point in time, the server can see the plain text, so we’re mostly concerned about future changes to the data.
Now, when a user first logs in, if their keys were generated for them, their private key is rotated. They can still access data previously encrypted to them, but any server that stored off their initial private key will find it useless.
All of this is done under the hood so the user doesn’t need to do anything special or even to know about the keys to keep their data safe.
Bonus Features
Performance
In the last year, we’ve put a lot of effort into performance for both SaaS Shield and the Data Control Platform.
For SaaS Shield, we moved our Tenant Security Proxy from NodeJS to Rust and saw a 60% speedup from that. We then added support for batch operations with automatic multi-threading on both the client and in the server.
We updated the Data Control Platform’s rust library to add asynchronous interfaces and non-blocking I/O, so embedding applications can take advantage of the parallelization available in their tasks to achieve higher performance and throughput. Most of our SDKs derive from this library, so they provide similar opportunities for performance increases.
Finally, for the Data Control Platform, we added client-side caching of public keys so that large batch encrypt operations (such as on initial imports) can re-use public keys without making network calls. With cached keys and when run in threaded mode, our throughput is now about 10ms per encryption operation. We’ve also provided raw benchmark results and instructions on our libraries for how to run the benchmarks yourself.
Protobuf Support
We added support for protobufs in the Data Control Platform and a mechanism for classifying data within those protobufs. This dovetails with the policy features and allows the classification of data at a protobuf definition level.
Memory Protections
The recrypt library, which holds the encryption routines that underpin most of our products, gained memory protection techniques. On supported platforms, to the extent possible, we are able to prevent memory that holds private keys and plain text from being written to disk as part of memory swapping or core dumps. This better protects secrets that are only ever intended to be in memory briefly.
Looking back and looking forward
Reading through all these updates and new features, I’m excited by what we’ve accomplished. Our team spends a lot of time improving our products based on customer feedback, and it shows.
The Data Control Platform and SaaS Shield products are the answer to many modern data privacy challenges faced by software companies. As those challenges evolve, so does our product line. We’re committed to listening to our customers, learning from industry peers, and building a company and movement focused on making the world a safer place with data control.
If you are looking to up your data privacy game or to build your next application with privacy at the core, we’d like to hear from you. Let’s talk.