Deidentifying Data: The Fool's Trap
Personally identifiable information (PII) is now regulated nearly everywhere in the world. But there’s a way to avoid these laws that appears deceptively easy. If personal information isn’t linked to identifiers like name, address, and email, then it isn’t considered PII; meaning, there are no restrictions on sharing, mining, selling or keeping of that data.
Regulations like GDPR expressly allow this approach to privacy. Specifically, Article 32, Security of processing, requires “the pseudonymisation and encryption of personal data” and Article 4 defines pseudonymization:
‘pseudonymisation’ means the processing of personal data in such a manner that the personal data can no longer be attributed to a specific data subject without the use of additional information, provided that such additional information is kept separately and is subject to technical and organisational measures to ensure that the personal data are not attributed to an identified or identifiable natural person;
Sounds easy, right? But you’re still culpable if someone is able to take your deidentified or pseudonymized data and re-identify it. In other words, if someone can figure out who a set of data actually relates to, that’s your fault as you did not sufficiently anonymize it. Which means you need to be very careful here, or be ready for some fines…
There’s a trap waiting for companies that share data they believe to be anonymous. Just because the direct link to an identity is removed doesn’t mean that there aren’t indirect links that can be found. In fact, I guarantee that such indirect links exist for all but the most trivial and small datasets.
When we consider whether some set of data is anonymous, we almost always evaluate it in isolation. It’s extremely easy to forget or ignore what could happen if that data was joined to other sources of data. And this is the crux of the problem.

The New York Times did a great job of illustrating this in their article, ”Your Apps Know Where You Were Last Night, and They’re Not Keeping It Secret.” Weather apps among others sell your anonymized location data. But this data is trivially re-identified by joining location paths to public data sets like the white pages. Very few people go back and forth between my home and my office (when going to an office was a thing). Picking me out of a bunch of location data is pretty easy. In a giant stack of anonymized locations, if you follow any given thread, there will be strong clues about who that person is, which can lead to all sorts of unintentional disclosures.
But it isn’t just location data. Clues to decode personally identifiable data are everywhere. While privacy risks will never be zero, when it comes to sharing data, we need to default to a much higher degree of data protection for our datasets than may appear necessary when looking at any one dataset in isolation.
This is not an academic postulate. Geneticists have re-identified people from “anonymous” datasets of DNA, and scientists have also re-identified individuals from “anonymous” datasets with just a few characteristics.
This is the age of “big data.” People generate it rapidly and companies collect it greedily. For example, people will take 1.4 trillion (Per Mylio) photos this year globally. That’s staggering. And 2.6 billion users (per Zephoria) interact with Facebook every month with 2.3 billion of those users interacting daily. I wonder what data in there could join back to financial, health, travel, and other data sets. Quite a lot, I expect.
When sharing “anonyized” data, you have to ask yourself whether things like facial recognition, location info, marketing profiles, demographic data, and other data sources could be paired to yours to enrich it and ultimately to re-identify it.
Here’s another toy example. Suppose we have a list of bank account balances, but the names are blanked out. That’s harmless, right? It doesn’t have transactions or locations or names. No one will know who is who, right?
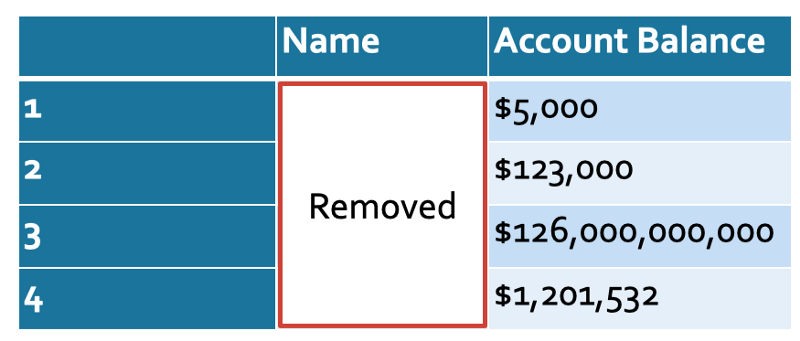 Anonymized bank data. Wait… I wonder who #3 is?
Anonymized bank data. Wait… I wonder who #3 is?
Except that pesky Forbes likes to publish data about the holdings and net-worths of very wealthy people. Jeff might want to change banks after this.
Which brings us to another point: the bar for failure isn’t having all of the records re-identified with 100% certainty. It’s having any of them reidentified or even narrowed down to just a couple of people. So that outlier data can compromise your entire approach. Data like this has the potential to create huge liabilities for companies who rely too much on deidentification or pseudonymization.
The challenge of joining datasets is especially relevant today as government entities around the world attempt to trace and control the COVID-19 outbreak. Extensive location tracing is generating incredibly large data sets that could potentially be sold to or shared with a variety of corporate and government entities. Or stolen by hackers. And even if that data is anonymized, it likely includes location data, which we already know is very susceptible to re-identification.
Americans are already skeptical of sharing additional data with tech companies like Apple and Google via a COVID-related app. And they are right to be worried. A 2013 study published in Nature found that four unique data points collected from cell phones as people traveled was enough to identify 95% of individuals.
 Cryptograms are letter-substitution puzzles that are similar in many ways to the puzzle of reidentifying “anonymized” data sets.
Cryptograms are letter-substitution puzzles that are similar in many ways to the puzzle of reidentifying “anonymized” data sets.
So the next time you’re using an app and they tell you that they only share your data after anonymizing, pseudonymizing or deidentifying it — run away. Run far and run fast unless you truly don’t care about the data being shared getting traced back to you by marketers, hackers, Governments, researchers, or curious puzzlers tired of cryptograms and ready for a different challenge.
And for companies who hold PII or peddle in personal data, we say this: you need to go farther by fuzzing or bucketing values, by using strong encryption controls, and by minimizing what you store and share. Don’t look at your anonymized data set without imagining what other data sets out there could be used to unmask the people in it.
This blog is part of a series based on a conference presentation I gave earlier this year at SnowFROC. You can watch the full presentation below.