
The Hidden Dangers of Face Embeddings: Unmasking the Privacy Risks
One of the classic applications of machine learning is facial recognition, where a model is trained to find faces in images or videos and capture identifying information about them. Facial recognition has many applications, but some of the most useful ones involve taking facial features and matching them against other useful data previously collected and tied to the same face, which requires creating an embedding. Unless your facial recognition system is simply marking where to find faces in pictures or video, it’s probably generating an embedding from each face it identifies.
What are embeddings?
An embedding is simply a big list of numbers, typically represented as a vector of 300 to 4096 numbers between -2 and 2. That list of numbers represents a machine learning model’s complex interpretation of the meaning in the input. Inputs can be text, images, audio, photos, and more. It’s a distillation of the extracted meaning – the model itself may have tens of thousands or millions of traits and categories – so each value in the embedding has a lot of information packed into it. This density of information isn’t something a human can follow, and because of that, embeddings are frequently (incorrectly!) thought of as meaningless if exposed.
Embeddings are then mathematically used to find similar meanings across stored data, cluster data, find anomalies, and so forth.
Once an embedding has been created for a face, it can be compared to other embeddings that were generated for other faces. Ones that are “near” each other (mathematically) are similar faces and ones further away are different faces.
This technique enables looking someone up using an image of their face, linking it to information about that person, and using that for some of the most exciting (and scary) applications of facial recognition.
Privacy and embeddings
In this blog post, we’re going to reverse embeddings back into recognizable faces. We’ll demonstrate how we could take a database of face embeddings and convert them back to privacy-invading photos. We’ll then show you how to prevent attacks like this one.
Protecting embeddings is important because the number of places capturing and storing this information is growing. There’s already been tremendous abuse in at least one case where the FTC stepped in. As more and more stores, governments, and others add facial recognition functionality, the likelihood of abuse or accidental exposure of these embeddings grows as well.
Attacking embeddings
If an intruder stole embeddings from your database, they could immediately compare them with their own database of embeddings to identities for a match. Then they could associate whatever information you had connected with that identity (customer bases, medical data, buying habits, etc). An encrypted embedding (discussed below) wouldn’t also passively protect against this. That attack requires the intruder to already have their own database of identities to embeddings, instead we’ll talk about attacks that involve only the stolen embedding.
There are several different forms of attacks we could mount on facial recognition embeddings that attempt to get as close as possible to the input face (called an inversion attack). Some of the more sophisticated attacks involve training a machine learning model on the embeddings themselves, so it can produce a face when given an embedding as an input. Those attacks require a significant amount of work to create, but there’s at least one attack that doesn’t even require us to train a model while still getting good results, which is what we’ll be doing here.
We’re going to take a facial recognition embedding and find the closest pre-generated face we have to start from. This is purely a speedup step as the starting face could be random. Then we make small tweaks to that face, generate a new embedding, and see if the face (embedding) is more like the target or less like it. Rinse and repeat as many times as we’d like.
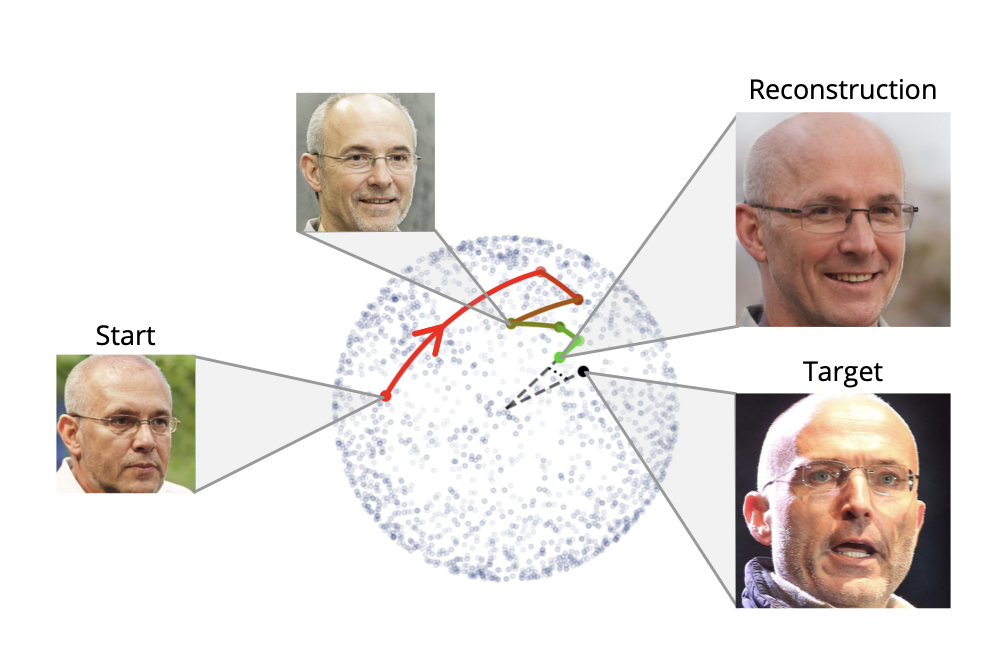 from “Realistic Face Reconstruction from Deep Embeddings” by Edward and Joshua Vendrow
from “Realistic Face Reconstruction from Deep Embeddings” by Edward and Joshua Vendrow
This approach comes from the paper “Realistic Face Reconstruction from Deep Embeddings” by Edward and Joshua Vendrow and makes use of a modified version of their published implementation of that paper. The code we used to do this is on Github and you can try it yourself in a browser using this Colab notebook.
Results of the attack
We ran our attack with a picture of Tom Cruise as the input for 400 iterations. This run took 10 minutes and resulted in this:


We upped the iterations to 2000 because each try was still getting closer and ended up with even better results after 40 min:

While neither is exactly the face that was input, they’re both pretty close, especially in facial structure and features. Close enough that if someone had stolen this embedding they’d have a very good idea of what the input face looked like.
How do we prevent it?
Encrypting the vectors with IronCore Labs’ open source (AGPL) vector encryption library, Cloaked AI, prevents attacks like this as well as the ones that train an inversion model.
We ran the same attack as before on the same picture of Tom Cruise, but this time we encrypted the embedding with Cloaked AI before attacking it. We still ran it for 400 iterations for comparison’s sake, even though the results weren’t improving across iterations. This run took 10 minutes and resulted in this:

As you can see, the reversed image isn’t even close to the original picture this time.
The encrypted vectors use much larger numbers than the original vectors, but even if we normalize those values to bring them into the expected ranges, the face still doesn’t get close. The attack essentially produces a random face with no relation to the original.
Isn’t the embedding useless when encrypted? No!
Even though we’ve made the embedding much more secure against attack, we’ve used encryption that mathematically preserves its approximate relative distance from other embeddings encrypted with the same key. That means that all the things you’d want to use the embeddings for such as similarity based retrieval, matching, classification, anomaly detection, etc., will keep working! If you don’t have the right encryption key, you can’t meaningfully do any of those things, and you can’t reverse the embeddings anymore either.
Embeddings are sensitive
Embeddings are an enormously important source of information. Faces can be used to track where people have been, what they’ve purchased, who they associate with, or even what they’ve paid attention to in a store. This is incredibly invasive information, and protecting that data is critical. Luckily, it’s also easy to do with an inexpensive open-source software library.
This same process can apply to any embeddings, not just facial recognition ones. Up next in this series we’ll take a look at attacking text embeddings, which have been made very popular due to hybrid search and retrieval augmented generation (RAG). RAG makes it possible for natural language queries to find relevant information to ground and inform an AI that can then answer the question.



