
"Embeddings Aren't Human Readable" And Other Nonsense
In the last month, I’ve heard this and similar things a number of times. Senior leaders at vector database companies told me vector embeddings were like hashes and were meaningless except when compared to each other. This myth is a frightening misconception when repeated by those who should know better, considering the sensitive nature of the data they hold.
What are embeddings?
If you’re not familiar with embeddings, they’re a type of inference (a conclusion, if you will) produced by AI models that are meant to be stored and used later. They’re sometimes called the “memory” of AI.
At a low level, an embedding is merely an array of real numbers with values that look something like this:
[0.123, -0.345, 0.567, -0.008, ....., -1.284]
And although you and I may not see meaning in those numbers, they represent important semantic information about the model inputs. They could represent a snapshot of a face, notable information about an image, the meaning of a sentence, a snippet of code, and much more. They’re useful for facial recognition, clustering, recommendations, classifications, and various types of search.
They’re also increasingly being used as part of a process that “grounds” large language models to keep them from making stuff up (hallucinating) in chats.
Just unintelligible numbers?
The fact that they’re stored as numbers has led a number of people to tell me that they don’t think embeddings are sensitive data. If embeddings are generated from private photos or confidential text, then they’re rendered useless, right?
If you look at a GIF in a text editor instead of in your browser, I dare say it would look meaningless to you. That’s because it’s stored in a machine representation that requires interpretation before a human can understand it. The Homer GIF here is just an array of decimal numbers like this: [..., 5, 1, 2, 6, 0, 3, 6, 2, 7, 9, 0, 3, 11, 2, 7, ...]. And if you think a bit deeper, you might realize that everything on your computer is really just arrays of 0s and 1s anyway. Not a strong argument for them not having meaning.
And in fact, embeddings are notable for how much data they actually retain. It just isn’t an exact reproduction of the input.
Embeddings are impressions
If you think of embeddings as being impressions of data rather than the original data, that intuition aligns more closely to reality. Just as we might paraphrase something we’ve read because we don’t remember the exact original words, so it is with embeddings, which capture impressions and meanings.
This is why people sometimes say that embeddings are “lossy,” meaning that they lose information, and why they argue that that lossiness means there’s no recovering the input.
Embeddings are “lossy”
Embeddings aren’t a perfect snapshot of their inputs, but that doesn’t mean they aren’t sensitive.
Consider again the GIF, which can be rendered at different levels of quality. With lower quality, the image will be blurrier and less distinct, but the file size will be smaller. A human will still be able to recognize what’s in the image even if some details are lost.
It’s the same with embeddings; some have higher fidelity in the form of larger dimensions (more numbers in the array – say 1,500) or lower fidelity (dimensions nearer to 300). The number of dimensions roughly correlates to the amount of detail the model is able to capture, but in a less fine-grained approximation.
The reasoning around lossiness implying that inputs can’t be recovered is faulty, as we’ll see in a moment. For now, imagine them like blurry photos that modern photography programs using AI can make crisp again using educated guesses.
Embeddings are one-way (like a hash)
And finally we hear people saying things about how embeddings are unidirectional. This is a misguided and pervasive idea that information can be encoded to embeddings, but not decoded back from them.
Embeddings that capture similar ideas are similar to each other (as measured by various measures of distance between vectors). So you can search over embeddings with a query to find sentences (or faces or whatever) that are similar to the input. So obviously we can make some pretty good guesses about those inputs in this way and they leak a lot of data no matter how you slice it.
But how much data do they really leak? To answer that, we’ll look at the academic research that’s attacking embeddings.
Embedding inversion attacks and other academic work
Attacking AI systems is a relatively new field of study. Most of the papers we’ve found on the topic (especially around embeddings) are from the past few years. None before 2017 that we’ve spotted. This field is often called adversarial AI, and it’s broken up into a ton of different techniques from prompt injections to the ones that are most relevant to embeddings:
- Embedding inversion attack – decodes embeddings back into their source data (approximately)
- Attribute inference attack – extracts information about the source data not expressly part of the source material, such as inferring sentence authorship based on embeddings
- Membership inference attack – can be applied directly to models, but in this case uses embeddings to extract training data from the embedding model without knowing anything about that model
For now, we’ll focus on embedding inversion attacks.
One important paper in this space from 2020 is ”Information Leakage in Embedding Models” which makes this claim:
Embedding vectors can be inverted to partially recover some of the input data. As an example, we show that our attacks on popular sentence embeddings recover between 50%–70% of the input words (F1 scores of 0.5–0.7).
Now that’s astounding - the embedding is actually capturing the semantic meaning of those sentences, but they can still recover specific input words. They go on to say:
For embeddings susceptible to these attacks, it is imperative that we consider the embedding outputs containing inherently as much information with respect to risks of leakage as the underlying sensitive data itself. The fact that embeddings appear to be abstract real-numbered vectors should not be misconstrued as being safe.
Another paper published earlier this year takes recovery a step further: ”Sentence Embedding Leaks More Information than You Expect: Generative Embedding Inversion Attack to Recover the Whole Sentence.” This paper is accompanied by open source code allowing anyone to use their approach to reverse sentence embeddings. Essentially, they train an adversarial model on associations between embeddings and sentences and then use that to recover original meanings. They are focused on the semantic meaning more than words so that they can distinguish between “Alice likes Bob” and “Bob likes Alice” (to use their example) when decoding an embedding. Below is an excerpt from their appendix showing the performance of their approach against some specific embedding models and compared to some other attacks.
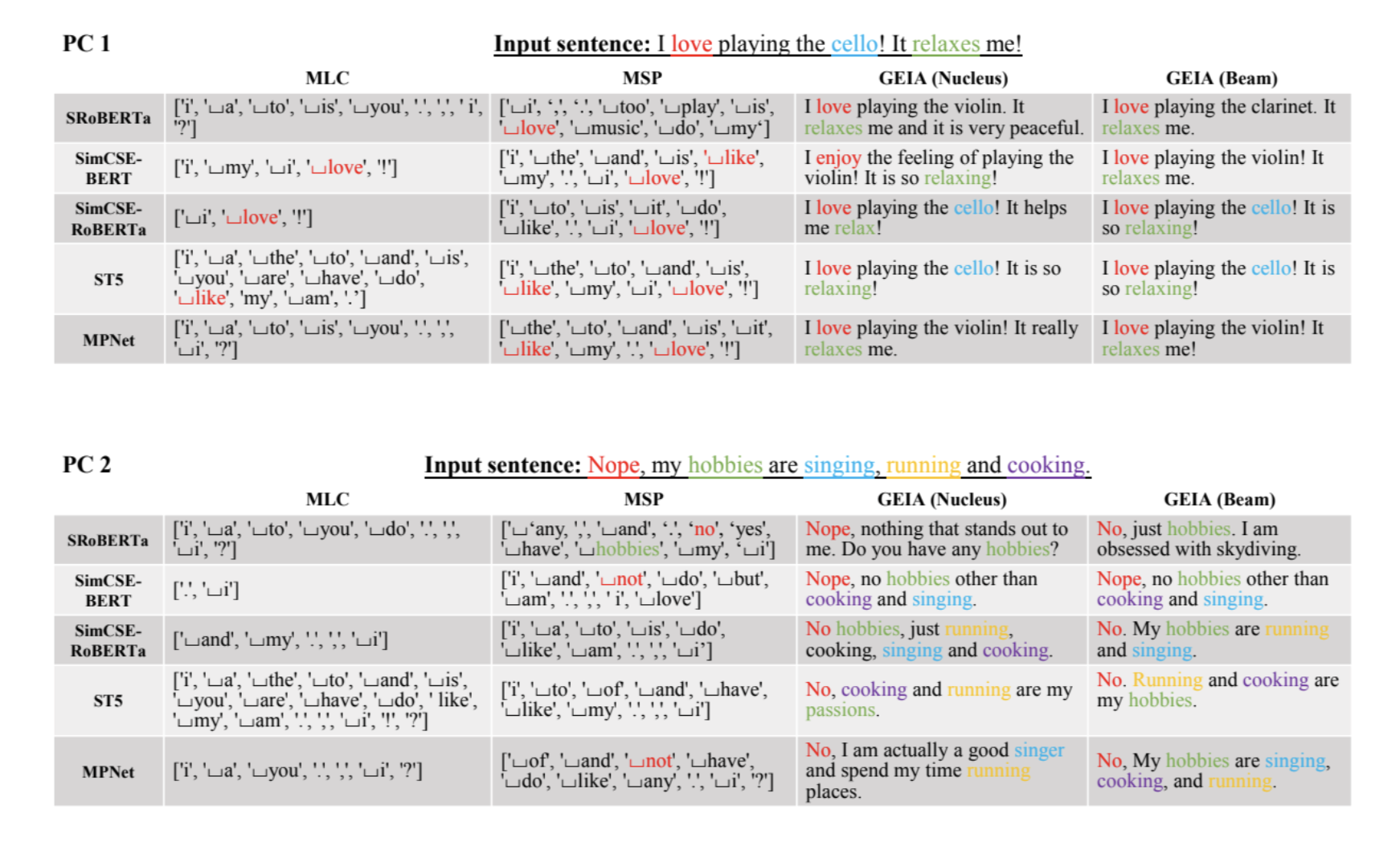
But it’s interesting to note that these ideas could be combined and another model could be used to correct and complete thoughts to recover not just specific sentences, but entire paragraphs at a time, ensuring they make sense and fit well together. If transformer models have taught us anything, it’s that context improves results. I feel confident we’ll see work doing exactly this in the near future.
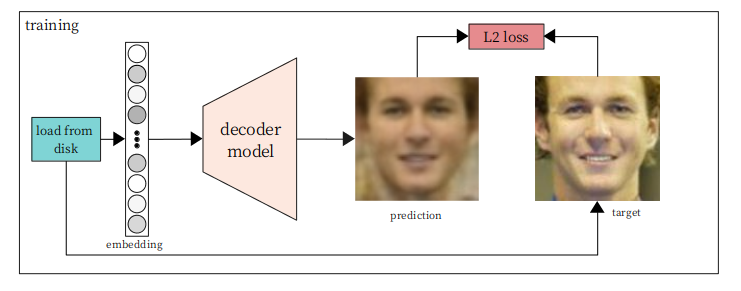
And finally, embedding inversions aren’t just a concern for text data. In the blog, ”Inverting facial recognition models (Can we teach a neural net to convert face embedding vectors back to images?),” the author shows that he can easily reproduce photos of faces just from their embeddings even when he doesn’t know anything about the model used to generate them:
To summarize, with 870 images, we’ve successfully set up a method to decode any embedding produced using a cloud-based face embedding API, despite having no knowledge of the parameters or architecture of the model being used. … We were then able to use all that to derive a way to design a general purpose face embedding decoder, that can decode the outputs from any face embedding network given only its embeddings and associated embeddings; information about the model itself not needed.
And finally, a paper out of Cornell titled ”Text Embeddings Reveal (Almost) As Much As Text” has this claim:
A multi-step method that iteratively corrects and re-embeds text is able to recover 92% of 32-token text inputs exactly … and also show that our model can recover important personal information (full names) from a dataset of clinical notes.
“Brute force” attacks
And because many of the embedding models are shared models, such as the model text-embedding-ada-002 from OpenAI and the commonly used SBERT models like all-mpnet-base-v2 from Microsoft, reversing embeddings can be even easier.
If you know or can guess what embedding model was used, you can build up a huge number of embeddings that tie back to original sentences and then simply compare a retrieved (or stolen) embedding to the corpus to find known sentences similar to the original unknown input.
Consider, for example, an attacker who gets into a public company and is able to download their embeddings. The goal of the attacker is to uncover whether the company will miss, meet, or exceed Wall Street’s expectations in an upcoming earnings report so they can trade its stock accordingly. Companies tend to use specific language when they talk about their earnings. Knowing that, an attacker could simply figure out query embeddings in a vector database with specific phrases looking for very near or exact matches. The idea is not dissimilar from how passwords stored as one-way hashes are “reversed” via dictionary attacks that hash each word in a dictionary for later comparisons.
Myths scorecard
So to summarize, MythBusters style:
| Myth | Verdict |
|---|---|
| Embeddings are one way like hashes | ❌ BUSTED, they can be decoded back |
| Embeddings are lossy | ✅ CONFIRMED, they are a thematically similar approximation of their input |
| The lossiness means you can’t recover sensitive info like PII | ❌ BUSTED, huge amounts of data can be recovered in very specific detail |
| Vector databases don’t hold personal info | ❌ BUSTED, they hold sensitive embeddings, and most of the time they are also holding associated data with those embeddings that may itself be problematic |
| Specialized expertise is needed to use embeddings | ❌ BUSTED, simple techniques can be used and open source tooling adds to the ease with which these attacks can occur |
Conclusion: Embeddings are human machine readable
These attacks are new and not fully refined, yet they are already extremely powerful. There’s a lot of reason to expect the attacks will get even better and the ability to invert embeddings will go mainstream – likely even for use cases that aren’t adversarial, such as grounding.
Much like you and I don’t record movies in our minds of what we see and hear, modern AI models don’t capture inputs perfectly. But they do capture key themes and meanings, which can be recovered out of the embeddings, and they are more than enough to be a major new area of risk for organizations handling confidential data.
So while you and I might see embeddings as just a bunch of meaningless numbers, that’s because we’re not looking at them through the equivalent of a GIF image viewer. To a machine, they are very readable and more than that, they convey a ton of meaning. Embeddings must be handled with the same care as other sensitive data – and possibly greater care given the duty people have to build new code with security and privacy by design and by default.

To protect vector embeddings in any vector database, even one hosted by someone else, take a look at Cloaked AI to encrypt the embeddings and their associated data.



