
Application-layer Encryption (ALE) Demo Using a Notes App
It can be difficult to demo encryption. If you do it right, the encryption is invisible to users, but the hackers only see garbage data. First you have to show the unimpeded frontend, then the inscrutable backend, and then to somehow convey solved difficulties of key management, audit trails, performance, memory management, and so on. But difficult or not, we’re going to try.
This blog is an overview of the more in-depth demo video that you can find on YouTube.
Understanding ALE
Application-layer encryption, or ALE, (see our explainer) provides clearly superior security. Data is encrypted before it’s stored so anyone with access to a data store, legitimate or not, only sees garbage.
Many people are afraid of ALE because the data stores can’t easily process over the data they hold. This can be countered by introducing newer encryption schemes with names like encrypted search and homomorphic encryption. These allow us to process over encrypted data if and only if you have the proper key.
And it’s not as hard as it sounds.
If you do it right, the encryption is invisible to users, but the hackers only see garbage data.
The Notes App
We’re demonstrating IronCore’s capabilities with a simple notes app. It has a list of notes, categories, the ability to filter to just a particular category, search, file attachments, and lastly, because no modern app is complete without it, a Gen-AI chat bot to personify your notes.
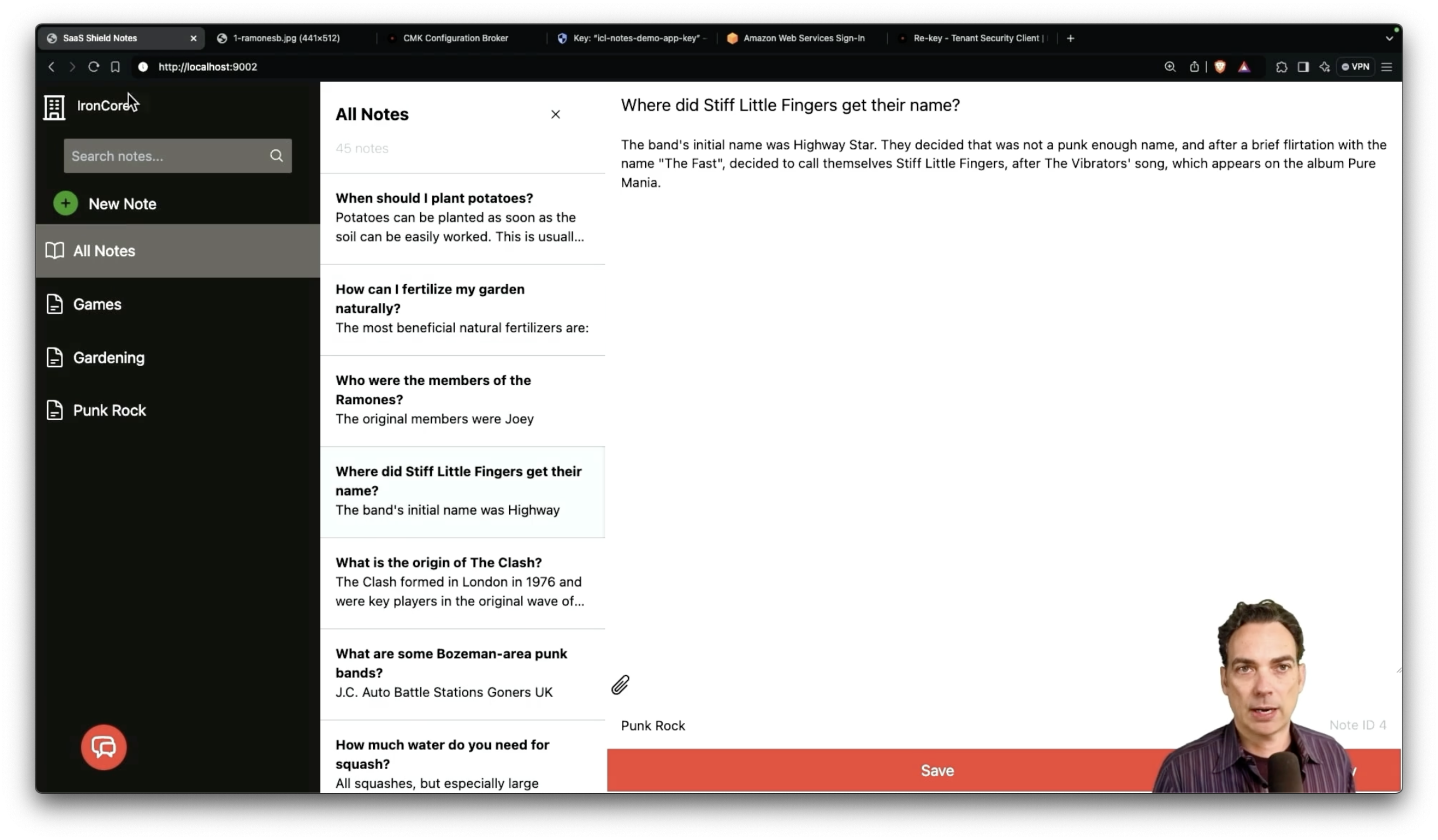
To the user, this functionality is familiar and normal. They can add new notes, edit notes, find notes, and generally organize their digital life. There’s no clue in the user interface that this app has a higher level of security than most notes apps. And that’s a shame, really, because I think if users could more easily see the levels of privacy and security, they’d reward apps that did better.
Of course, more sophisticated business buyers absolutely do scrutinize these things before buying, which is why you’re more likely to find good security in a B2B app than a B2C one, but I digress.
The App Architecture
Powering the notes app are four different tools:
- SQLite to hold information about the notes like title, body, organization ID, etc.
- Elasticsearch, which is powering our keyword search and the vector search needed for the chat bot
- AWS S3, which holds any note attachments
- Ollama, which runs our text embedding model (all-minilm) and our LLM (llama3.2:1b) locally
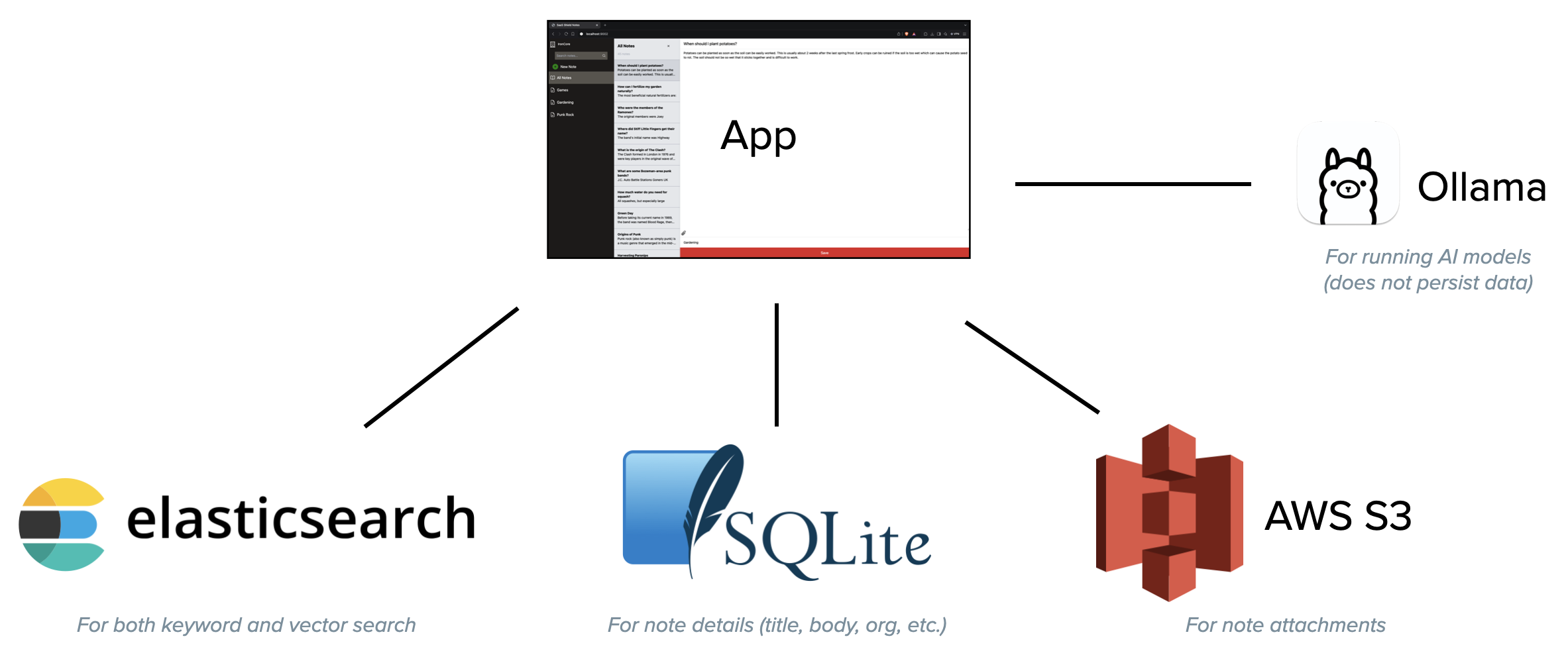
The app itself has a frontend serving HTML and a backend API service for interacting with notes, etc. We run all of this locally in docker containers. And because Rust is a core competency here, we wrote the services in Rust, though we could have chosen numerous other approaches.
The Security Architecture
We want to encrypt the note titles, bodies, attachments, and categories. And we want this to be encrypted no matter where it’s stored – even in search indices.
| Field | SQLite | Elastic keyword | Elastic vector | S3 |
|---|---|---|---|---|
| title | 🔒 (random) | 🔒(searchable) | 🔒(searchable) | - |
| body | 🔒 (random) | 🔒(searchable) | 🔒(searchable) | - |
| category | 🔒 (deterministic) | - | - | - |
| attachment | (reference only) | - | - | 🔒 (random) |
All sensitive data is encrypted before being stored. Much of it uses standard random encryption, meaning that the same thing encrypted twice gives two different results. In our case, there will be a unique key for every row of randomly encrypted data and we use AES-256-GCM to do the encryption.
The category field is encrypted deterministically, which means that for a given tenant (“logged in” organization in this case) and a given column of data, their single key is used. We encrypt this data using AES-256-SIV.
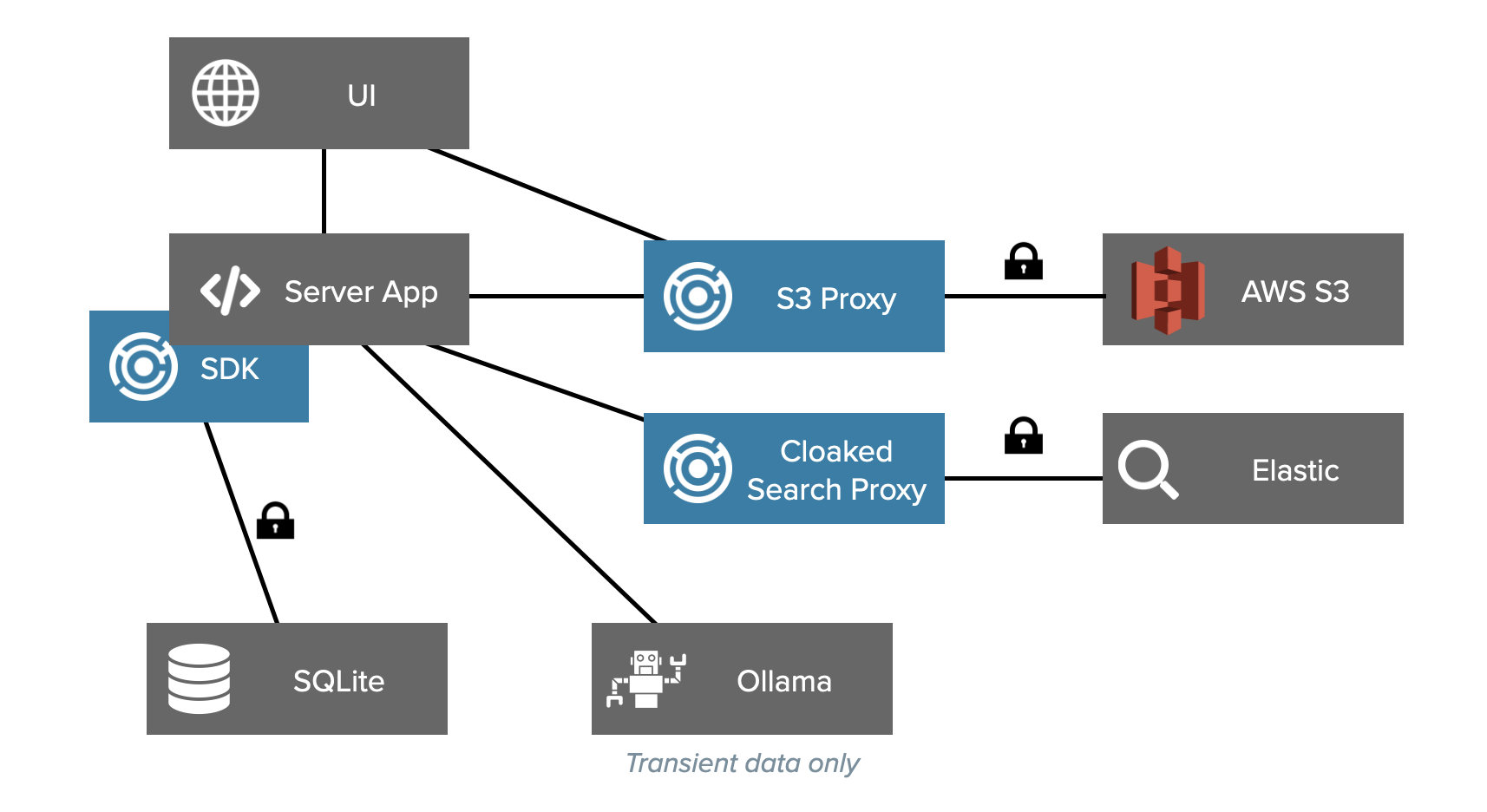
For the Elastic keyword search, we use a proxy, Cloaked Search, that does the encryption. That means we can use the Elastic SDK like normal and still protect our data. The same is true for the files stored in S3. By pointing to the S3 proxy, we can keep our code unchanged. For everywhere else, we use the IronCore Alloy SDK.
Key Management Architecture
Finally there is the question of the keys. Often, in example code, we and others will simplify the key management story and hard code a dummy key. But in this demo app, we’re demonstrating all of the functionality.
We have two different organizations with notes and each of those organizations has virtual isolation of their data because they use separate keys. If a SQL injection attack succeeded, for example, it wouldn’t ever be able to decrypt more than the current organization’s data, which is equivalent to giving every organization its own database.
This doesn’t only apply to multi-tenant SaaS applications, but to any application that has one or more segments of data protected by a key.
In the SaaS scenario, the vendor can hold the keys for each tenant in their own KMS. But when it comes to data sovereignty, privacy, and control, some customers want to hold their own keys. IronCore’s SaaS Shield platform supports any combination of these things. In this demo, we have each tenant holding their own keys.
To set this up, we signed up for a vendor account in SaaS Shield, and invited two customers (tenants) to take control of their keys.
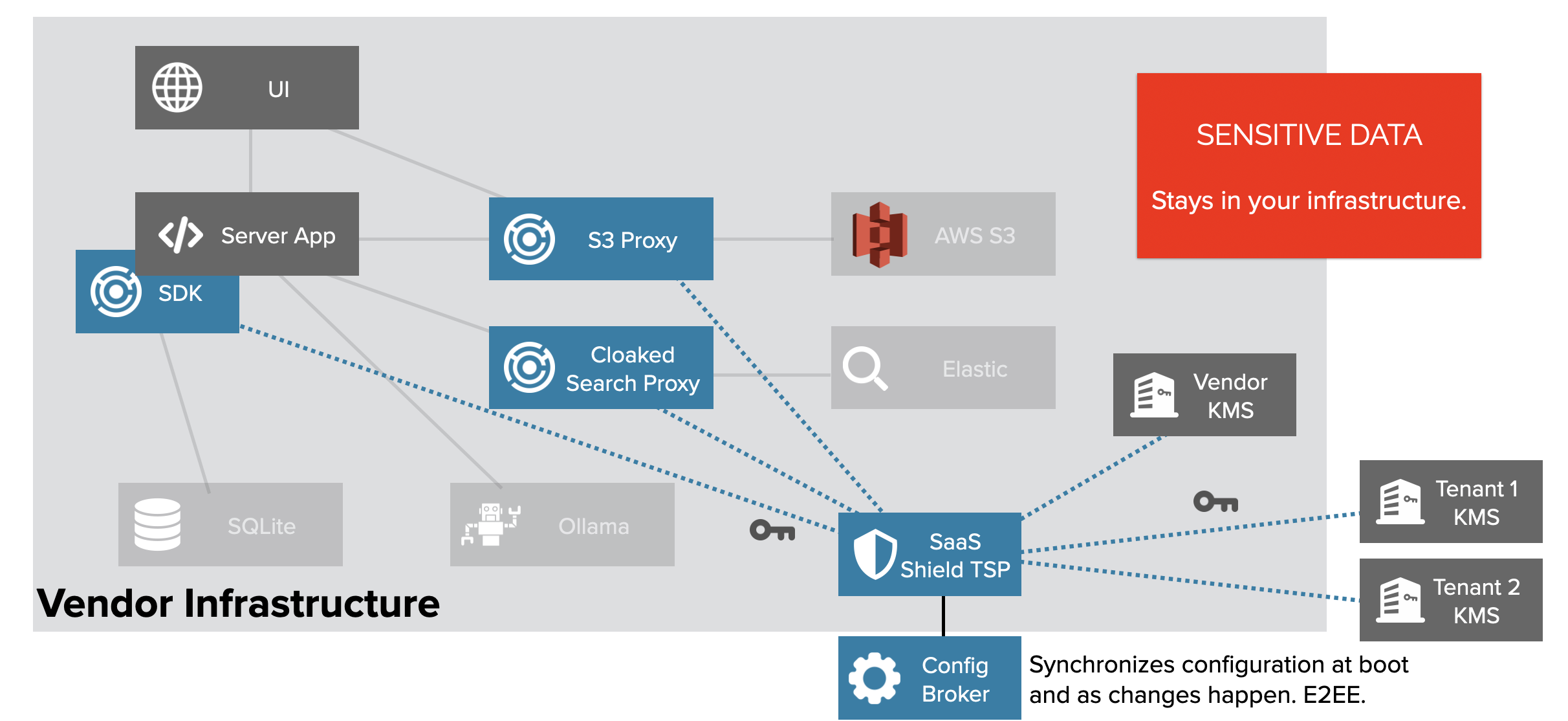
Now, regardless of whether we’re working from the SDK or via the various proxies, key management requests will go to the Tenant Security Proxy (TSP), which will call out as needed to various KMSes (and if we enable key leasing, those calls will never be in the hot path). Our Configuration Broker service’s sole job is to manage encrypted configurations, which it (and we at IronCore) can’t decrypt, to seed new TSPs with configuration information, and to push out updated configurations as needed.
Fetching Data From the Database
With everything running and the key management configured, we can start to see what’s happening.
If we look directly at the SQL database, we can see that it just looks like gobbledy-gook. In the category column we can see some repeated values, but not across orgs even though they have some of the same category names. We can see also a repeating string at the start of each column, which represents a header that we put on the ciphertext so we know how to decrypt it even as keys are rotated and customers change KMSes over time.
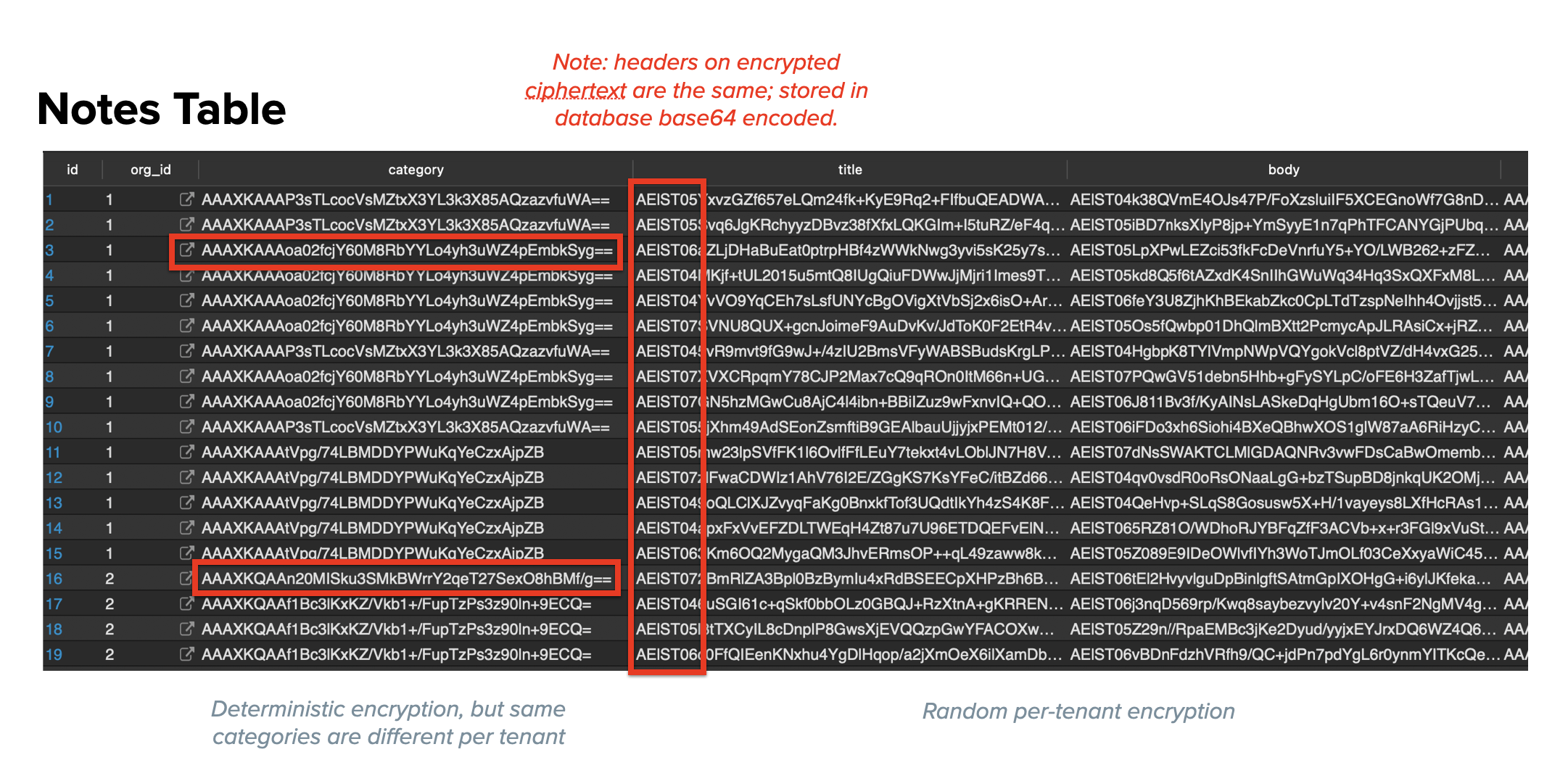
Not shown in the screenshot is another column, “EDEK”, which stands for encrypted document encryption key. Every row has one and decrypting data happens in two steps: first the EDEK is decrypted, then any of the fields can be decrypted. This is called envelope encryption, but we make it very fast.
When a user clicks on a category to filter, we deterministically encrypt the category name, then search for any rows with that same (encrypted) value. Note that we could have just made this an ID or something instead, but it wouldn’t be as nice for a demonstration. This sort of encrypted equality filtering is more often done for email addresses.
Searching Notes with Keyword Search
When we attempt to search the database, our code looks normal, but the proxy handles the fetching of keys, the encrypting of the query, and the decryption of the results. And the returned documents are the same as if no encryption was used at all.
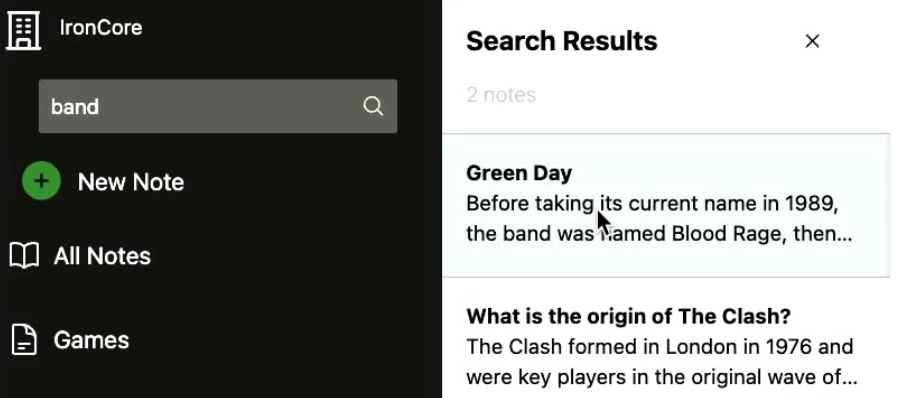
Despite the encryption, we support a lot of advanced queries and features from wildcards to phrases to phonetic matches.
| Feature | Example |
|---|---|
| Query logic | George AND (Coffee OR Mug) |
| Exact phrases | “IronCore Labs” |
| Prefix/suffix wildcards | Iron* |
| Phonetic matching | Kathryn == Catherine |
| Field and subdocument search | title:security author.name:george |
| Single and multi-tenant | Key per data segment |
| Complex result rankings | (weighted fields, etc.) |
| Multi-index | Search multiple indices at once |
But should that Elasticsearch instance be accidentally made public or otherwise accessed by an unauthorized person, there’s not much to see. A direct query for all records from Elasticsearch returns something that looks like this:
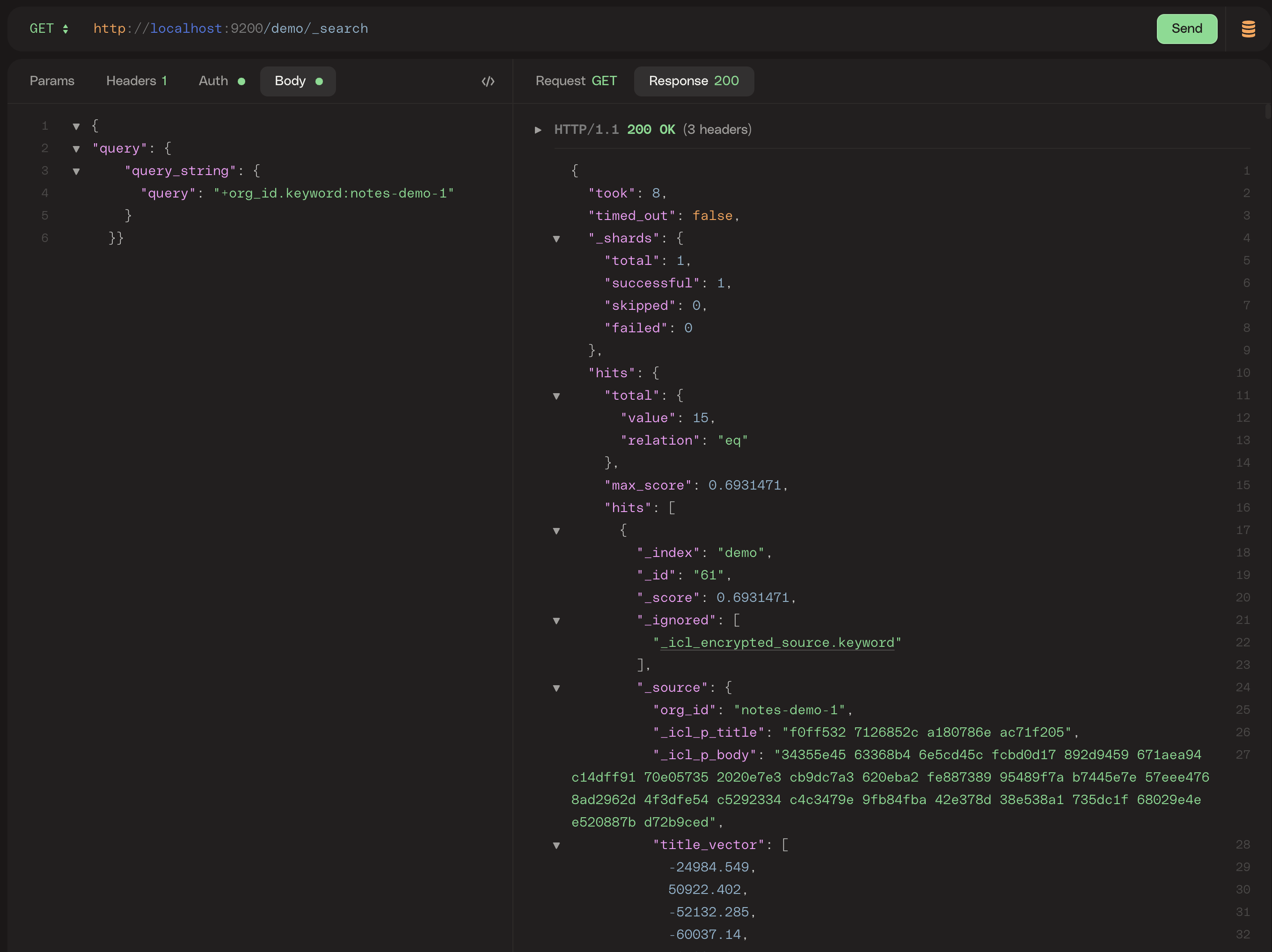
Encrypting S3 Files
Next up, we have the note attachments, which are stored in S3. For the demo, we just used images as the attachments, but they could really be anything.
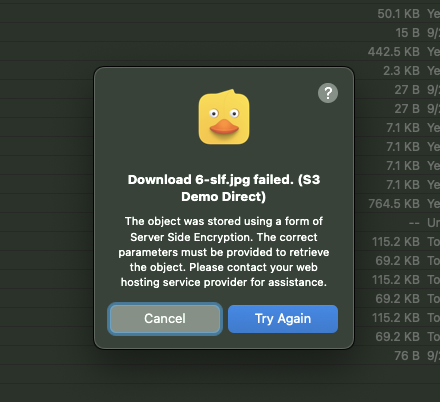
We configured the naming convention to have the org_id as the leading part of the filename, though the S3 proxy is quite flexible on how that is set up. When we attach a file, we upload it to Amazon using their Server-Side Encryption with Customer-Provided Keys (SSE-C) functionality. We do it this way so we can preserve most of the functionality provided by the S3 APIs.
There’s a separate key for every file and the correct key must be passed in to download the file. Amazon uses these keys and then immediately drops them from memory.
The consequence of this approach is that even if an S3 bucket is public (perhaps due to a misconfiguration) or if permissions on files are overly permissive, no one can download a file unless they have the correct per-file key. This lets us utilize things like pre-signed URLs so the browser can call to Amazon – still through the S3 proxy – with a pre-signed URL, bypassing and taking load off the app itself.
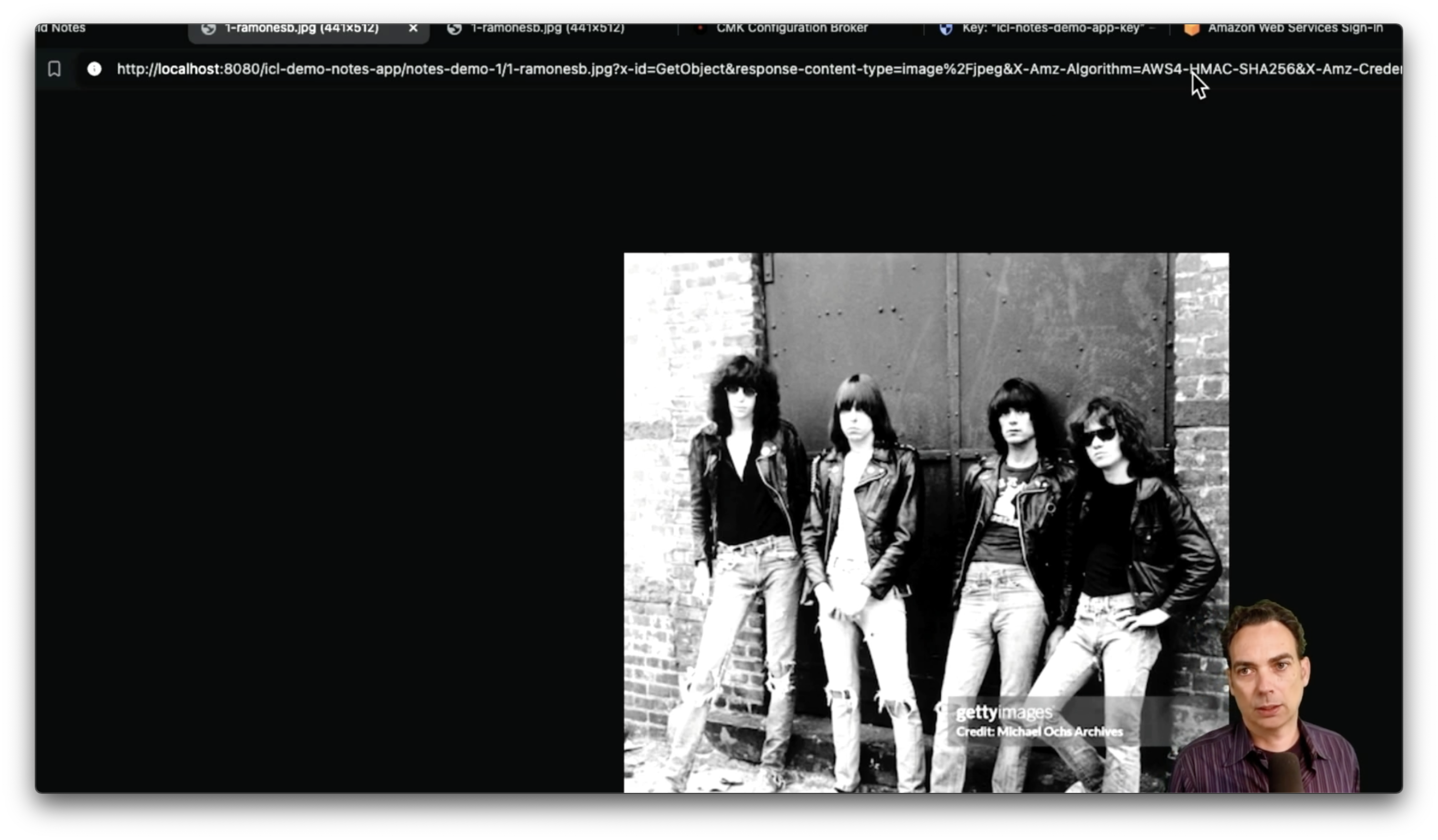
If you use something like the Cyberduck S3 client to go browse the bucket (given valid credentials), you can see what files are there (we didn’t encrypt the file names, but that’s not a bad idea), but attempts to download any encrypted files will fail:
Using a Natural Language Bot with Encrypted RAG
Finally, we can’t have an app without a chat bot (can we?). We are using minimal models for this test, but they get the job done. And we’re using a pretty basic RAG workflow (see our quick explainer if that’s not familiar) that uses vector search to power natural language querying. We take the top result from the vector search and embed the note contents in a prompt that combines with the user’s question and gets sent to the LLM.
Because the models are running locally and not logging queries, we can safely use them in an ephemeral manner. It isn’t perfect, but our private notes aren’t going to a third party or getting logged unencrypted somewhere.
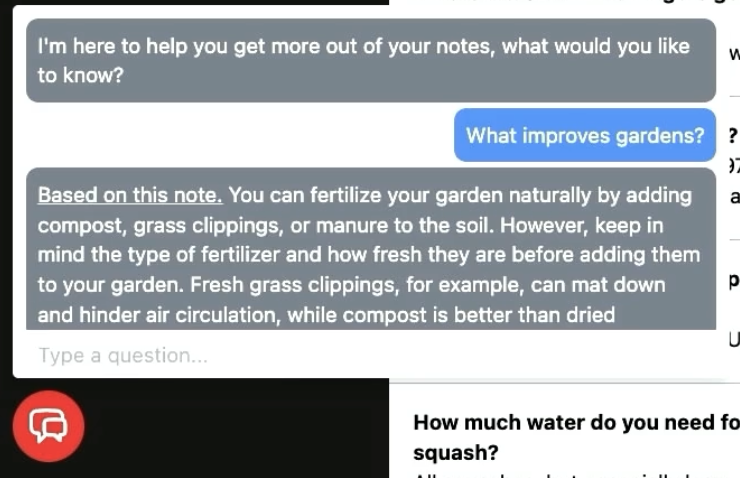
The secret sauce in this one is that the vectors have been encrypted before going to Elastic and the search query is also encrypted.
Why is this important? Because these vectors are shadow copies of the original data. They can be turned back into text using something known as an embedding inversion attack. There are also other attacks that can be run against unencrypted vector embeddings, such as inference attacks that figure out authorship of text. With encrypted vectors, this is no longer a problem.

A regular unencrypted vector embedding usually has numbers in the range -3 to +3 in a sequence from hundreds to thousands long (ex: [0.033, -1.288, -0.405, ...]). Encrypted vectors, on the other hand, tend to have much larger numbers, though large numbers do not by themselves mean there’s secure encryption.
Putting It All Together
We have a highly usable and useful notes app that’s multi-tenant and where the keys are stored offsite by customers so that an admin poking around doesn’t get to see anything private. The same goes for any scenario where a hacker gets into the infrastructure or gets admin credentials or where a misconfiguration makes something unintentionally public.
We didn’t show everything in this blog, so for another level of detail, check out:
IronCore’s SaaS Shield and related product family give developers the tools to make bullet-proof apps with server-side encryption. (Note: we also have a product for end-to-end and client-side encryption). We make it easy to put together best-of-breed and secure-by-design systems like this. And beyond that, we have a number of things that set us apart from anyone else in this space:
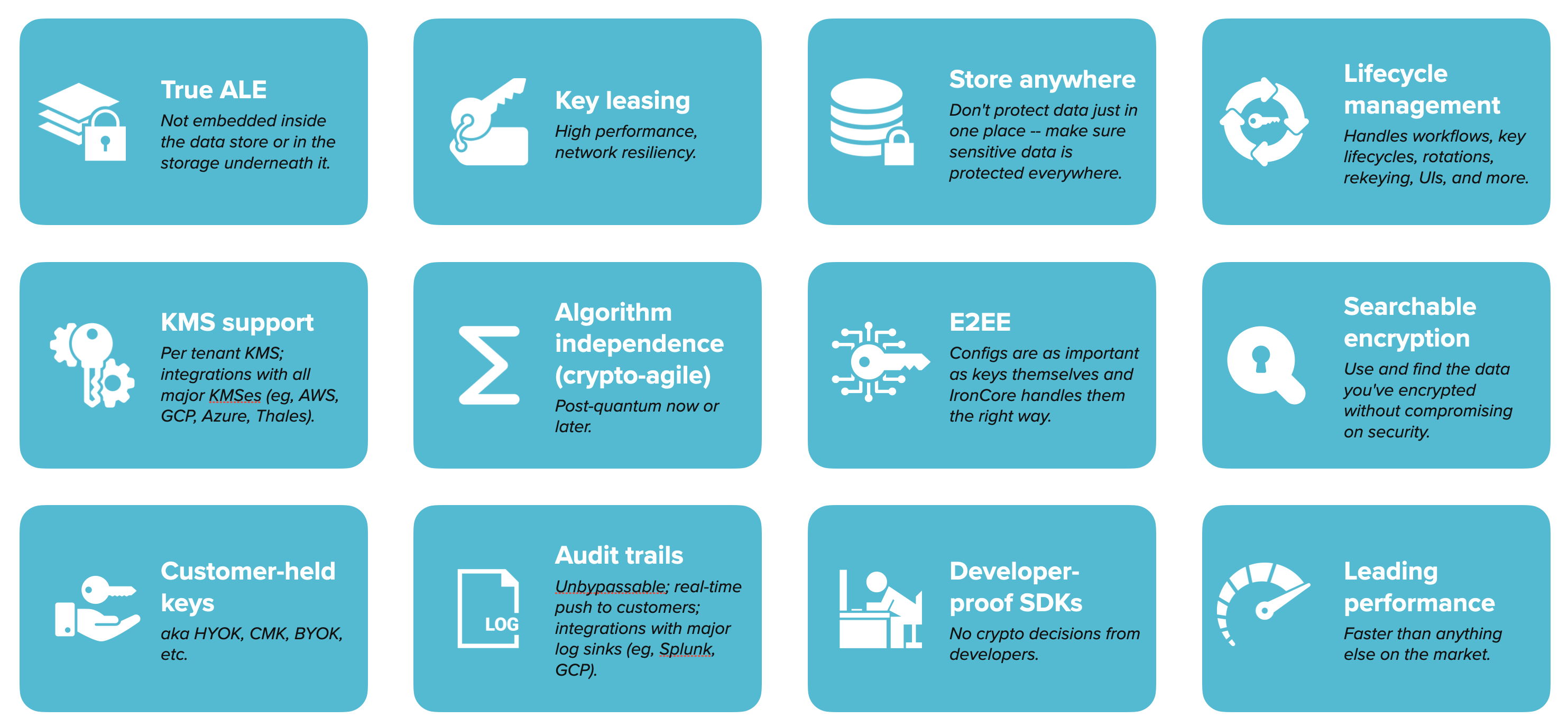
- True ALE: We leverage true application-layer encryption. Others use database plugins or low-level infrastructure encryption and try to convince you it’s ALE. The test is simple: given access to the storage service, do you see meaningful (unencrypted) data?
- Performance: we use key leasing, the Rust programming language, and thousands of other tricks to make our platform the fastest and most scalable option on the market.
- Store anywhere: we don’t constrain where your data has to live to keep it safe. We’ll encrypt your data regardless of where you store it.
- Lifecycle management: we handle all of the fallout from data and key lifecycles from handling key rotations to key migration to handling rekeying scenarios efficiently.
- Broad KMS support: we integrate with all the leading KMSes and you can mix-and-match across customers or data segments with one set of data ultimately protected by a key in Azure Key Vault while another goes out to an on-prem installation of Thales Ciphertrust.
- Crypto-agile: we give you algorithm independence, which is incredibly important in this age of changing cryptographic standards and emerging quantum computers.
- E2EE: we protect you even from us. We end-to-end (from browser to running tenant security proxy container) encrypt configs and keep any people from seeing them to keep keys safe.
- Searchable encryption: we make it easy to search over encrypted data and we don’t make you ditch the feature-full technologies you need.
- Customer held keys: we empower you to let your customers hold their own keys now or later when they need that.
- Audit trails: we keep full audit trails of all accesses to data and allow for those trails to flow directly to your customer for their own records.
- Developer-proof SDKs: we make sure developers can’t accidentally screw up the security of their system with poor cryptographic choices. We make it easy to use and handle everything.
- Transparency: much of our code is open source and we hide nothing up our sleeves. Our docs site gives full details on what we do and how we do it. This is in major contrast to our competitors who try to hide how they keep your data safe, requiring you to trust them implicitly.
If this is of interest to you, we’d be happy to give you a demo or answer your questions.



